Binaural Speech Intelligibility Model
Abstract: The common metrics for predicting speech intelligibility are described by the speech intelligibility index (SII) and the speech transmission index (STI). Both measures are determined using only a monophonic signal. While a single channel is suitable for evaluating speech intelligibility across transmission lines, predicted intelligibility values in room acoustics do not accurately correspond to subjective results. This is mainly due to the fact that, within a space, binaural cues are used to suppress the effects of reverberation and unmask noise. Monophonic measures do not adequately account for such phenomena. The proposed research aims to address this problem through the implementation of a binaural model. Current binaural models for speech intelligibility model a specific psychoacoustic attribute which do well under certain conditions, but fall short in other situations. The proposed model aims to account for the major detriments to speech intelligibility within rooms: background noise and reverberation. The noise unmasking algorithm will be based on equalization-cancellation (EC) theory, while implementation of reverberation suppression will be based on interaural coherence. Finally, the STI will be determined given the binaural signal-to-noise ratio values from the EC model, and the modified impulse responses from the reverberation suppression algorithm.
Binaural Processes:
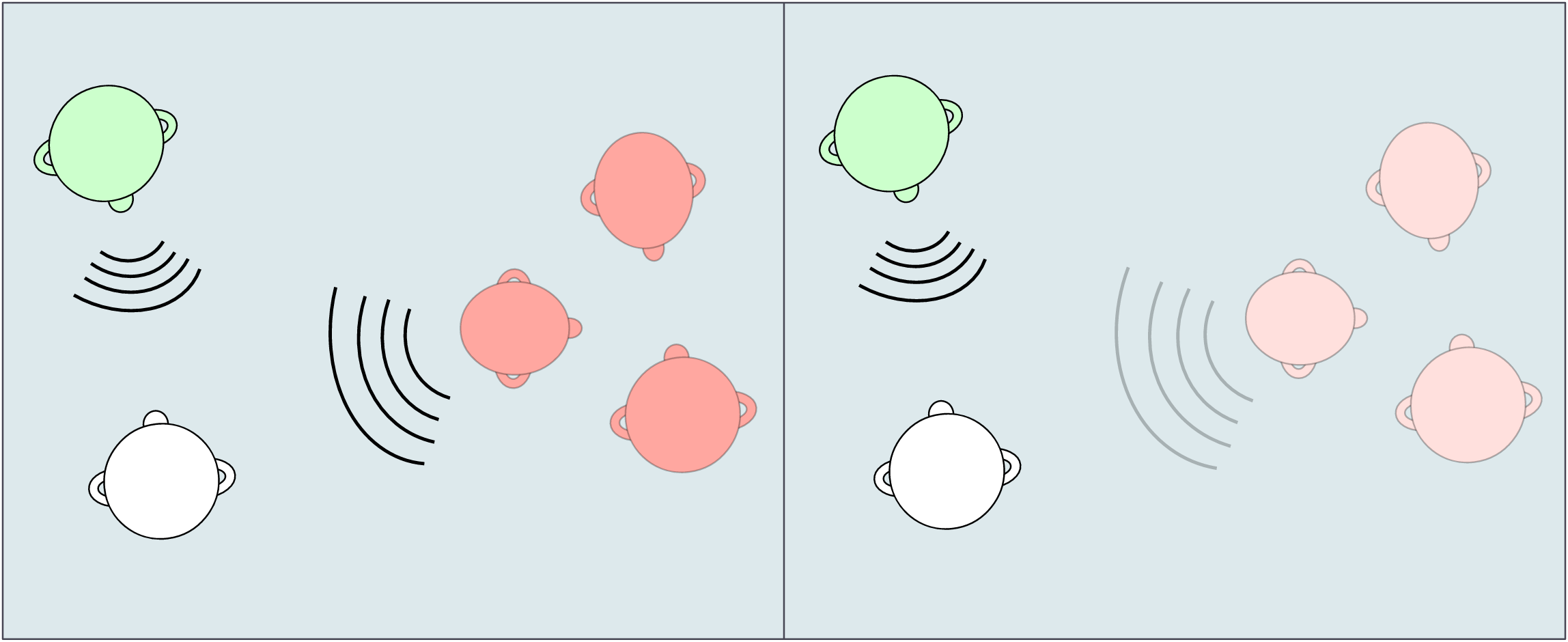
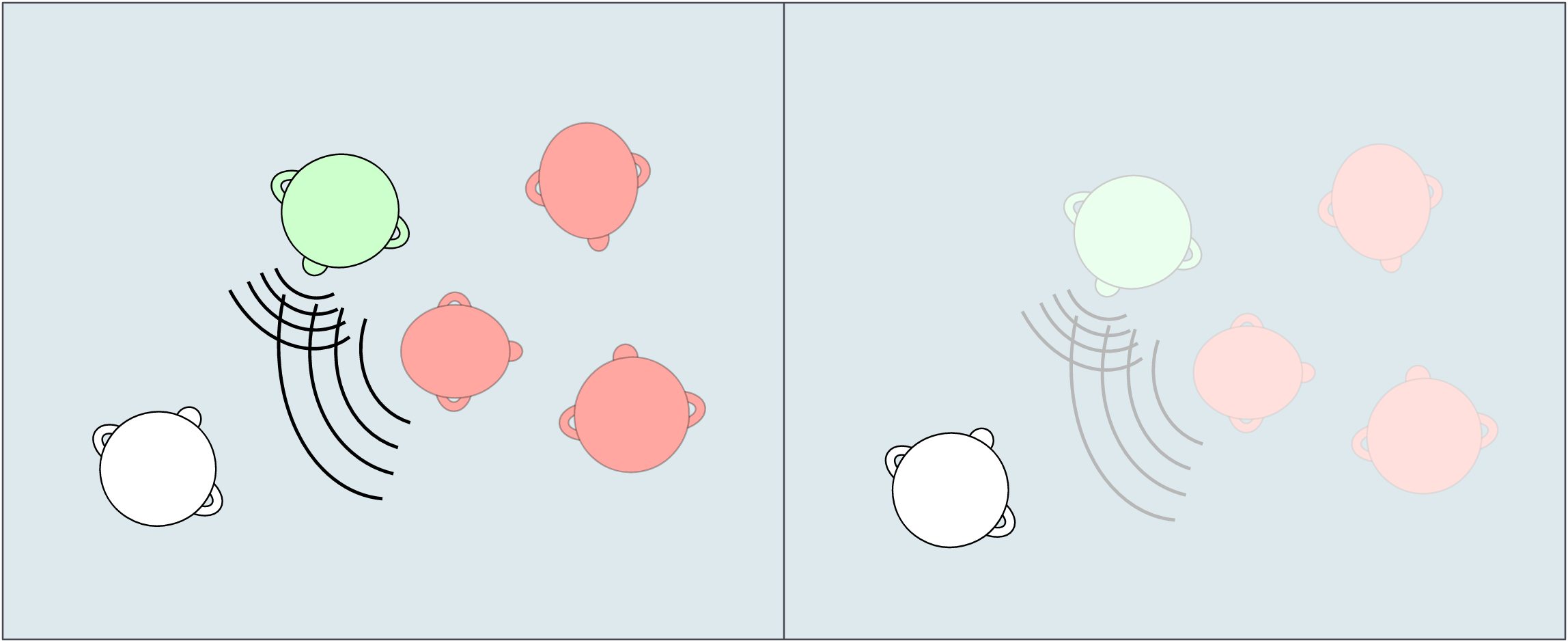
Noise unmasking uses the level and time (interaural) differences between the left and right ears to pick out the target speaker in a room with spatially separate noise (below left). This is commonly referred to as the cocktail party effect. If however, the target speaker and background noise are similar in location, the interaural differences are not dissimilar enough to effectively cancel the noise (below right).
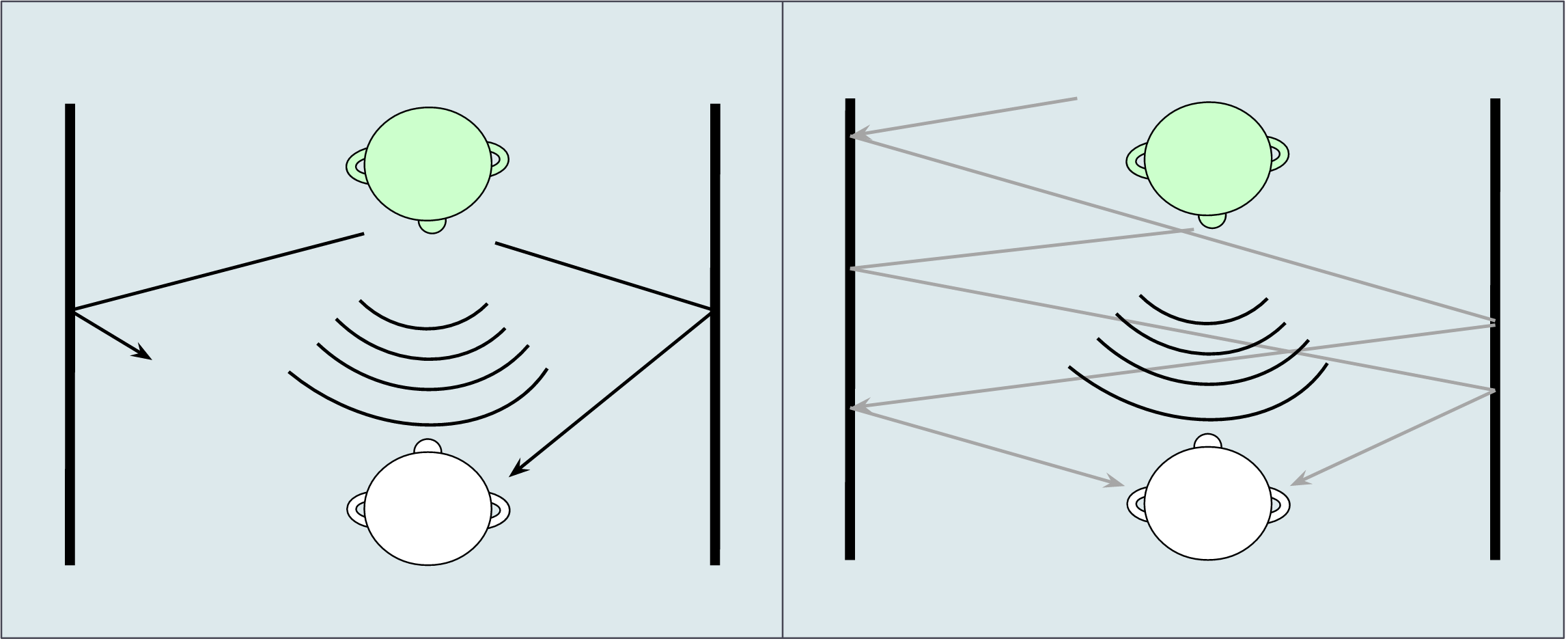
Room reverberation can be divided into two components: highly coherent early reflections that support speech intelligibility, and incoherent late reflections of a reverberant tail that often overlap the speaker's words. Due to the random nature of the late reflections, the brain is unable to correlate the signals, thereby allowing these reverberant signals to be suppressed.
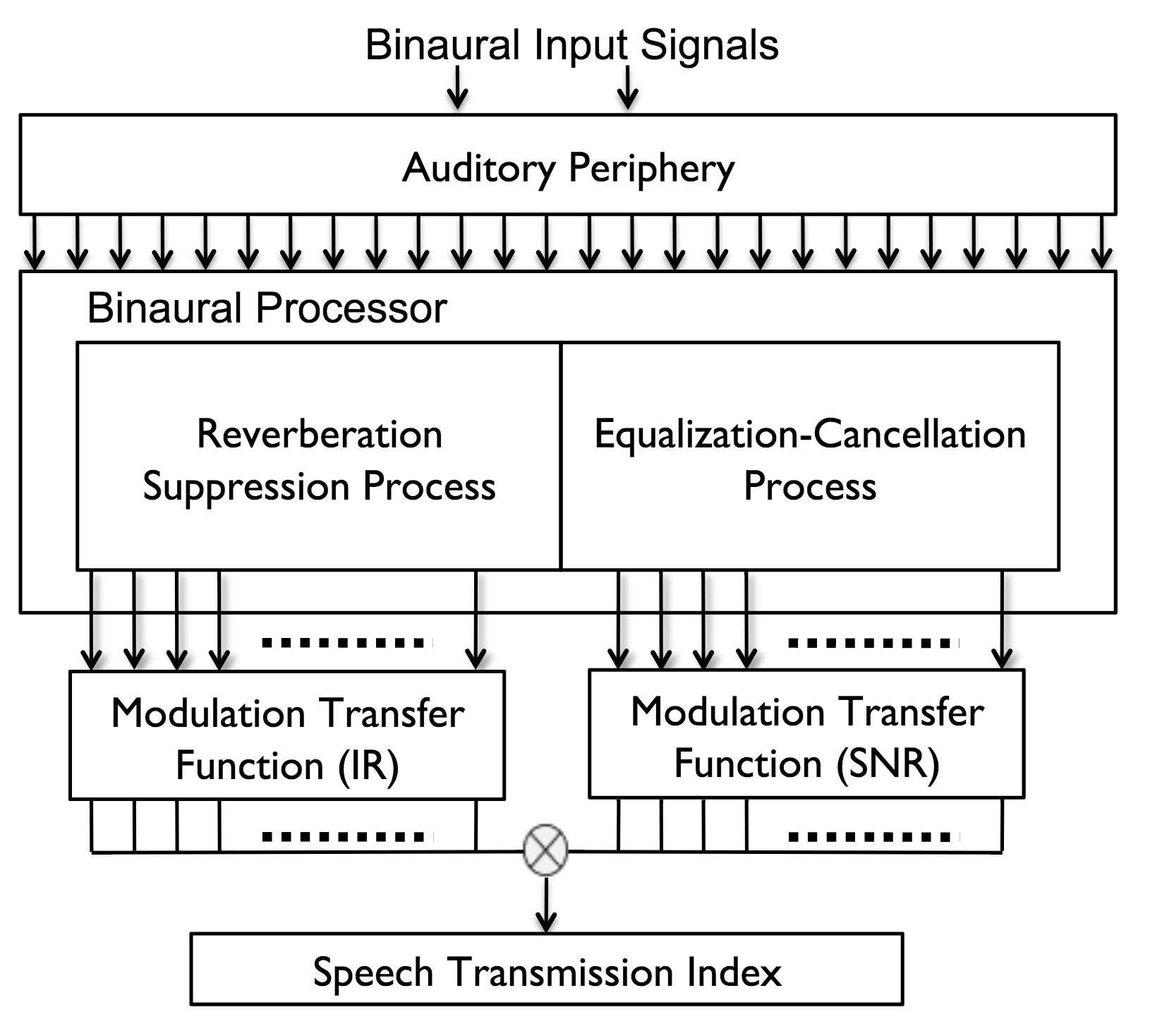
Model Overview: This psychophysical model built in Matlab takes binaural signals in different forms for each binaural process. The noise unmasking process takes a speech signal represented by spectrally-shaped noise, and a noise signal at a user specified dB level relative to the signal (SNR), both convolved with binaural room impulse responses that may or may not be spatially separated. For the reverberation suppression process, only the binaural room impulse response for speech is used. The signals are then passed through the auditory periphery to simulate the physiological behavior of the inner ear: a 30-filterbank Gammatone filter simulates the basilar membrane, and a low-pass filter simulates nerve firings of the inner hair cell. Once processed through the auditory filters, the binaural process takes advantage of interaural differences between binaural signals to unmask noise and suppress incoherent late energy (reverberation). The outputs from each binaural process are passed into their respective modulation transfer functions for ultimately calculating the speech transmission index. Using the Fairbanks speech intelligibility test convolved with binaural room impulse responses, I was able to run simulations through the model and use standardized methods of determining speech intelligibility against the listening results using the same room acoustics in order to tune the model.
Advisor: Ning Xiang, Rensselaer Polytechnic Institute, Department of Architecture. July 2011, Troy, NY.
Research presented at Hong Kong Acoustics Conference 2011 and Acoustical Society of America, Kansas City 2012 as an invited speaker.
Matlab